1. Perf工具介绍
Perf是一个非常实用且深入的性能分析工具,适用于从底层硬件交互到上层应用程序逻辑的全方位性能剖析
该工具的设计目的是为了帮助开发者分析应用程序以及内核本身的性能,寻找潜在的性能瓶颈,并根据此进行性能的优化
2. Perf工具原理
Note
Perf工具的原理的核心在于对Linux内核性能事件的支持和利用
- 硬件事件:
perf 能够利用CPU内部的 Performance Monitoring Units (PMUs)。PMUs是一组硬件寄存器,能够追踪和记录特定的微架构事件,如指令执行次数、缓存未命中、分支预测失败等。通过编程这些寄存器,perf可以设置特定事件的阈值,在达到一定次数后触发中断,收集此时的上下文信息,如CPU寄存器状态、PC指针(指向当前正在执行的指令地址)、进程ID、线程ID等
- 软件事件:
对于软件级别的事件,perf 利用内核中的计数器和 tracepoints。内核计数器可以追踪系统级事件,如上下文切换、页错误、任务调度等。Tracepoints 是内核中预定义的静态探针点,允许在特定位置插入额外的追踪代码,以便在关键内核操作发生时收集信息。对于软件级别的事件,perf 利用内核中的计数器和 tracepoints。内核计数器可以追踪系统级事件,如上下文切换、页错误、任务调度等。Tracepoints 是内核中预定义的静态探针点,允许在特定位置插入额外的追踪代码,以便在关键内核操作发生时收集信息
- 采样:
perf 工具主要采用采样法进行性能分析。它可以根据设置的事件类型和频率定期或者在满足条件时触发采样,每次采样都会记录下当时CPU正在执行的指令或函数信息。通过大量的采样数据,可以得出热点函数或代码段,从而找出可能导致性能瓶颈的部分
- 记录和报告:
perf 可以实时或事后分析记录的数据。它可以创建统计数据报告,展示CPU使用率、上下文切换、内存访问统计等信息,还可以生成调用图(火焰图)以直观地显示函数调用层级和耗时情况
- 跟踪:
除了采样之外,perf 还提供了更复杂的跟踪能力,允许持续记录系统的活动,包括系统调用、函数入口退出、irq处理等,这对于分析系统行为和优化系统响应时间非常有用
3. perf常用命令
最常用的perf命令及其功能理解如下:
annotate 读取perf.data(由perf record生成)并结合源代码展示详细的性能分析结果,包括CPU执行热点、函数调用栈等信息。
archive 使用perf.data文件中找到的带构建标识符的对象文件创建归档文件,便于后续对这些对象文件进行调试或者分析
bench 通用基准测试套件框架,允许用户定义和运行多种基准测试场景,用于评估系统在不同条件下的性能表现。
buildid-cache 管理perf用来关联二进制文件与其符号表信息的构建ID缓存,可以添加、删除或查看缓存内容。
buildid-list 列出perf.data文件中的构建标识符
c2c 共享数据C2C/HITM分析器:针对共享数据缓存一致性(Cache-to-Cache)和高速缓存命中(Hit in Translation)进行分析的工具,帮助诊断多核心间的缓存交互问题。
config 读取和设置perf配置文件中的变量,用于个性化perf的行为或指定默认参数。
daemon 在后台运行记录会话,适用于长期监控系统的性能情况。
data 提供一系列与perf.data文件相关联的操作,如检查文件内容、转换格式等。
diff 比较两个或多个perf.data文件,分析并展示它们之间的性能差异,常用于对比不同条件下系统的性能变化。
evlist 列出perf.data文件中的事件名称,这些事件可能包括硬件性能计数器事件、软件事件、tracepoint事件等。
ftrace 内核ftrace功能的简单包装器,允许实时追踪和分析内核函数调用路径。
inject 过滤器,用于向事件流中添加附加信息,增强事件的数据量和丰富度,便于更加深入地分析性能问题
iostat 显示I/O性能指标,如块设备读写速率、I/O操作延时等
kallsyms 在运行中的内核中搜索符号
kmem 用于跟踪/测量内核内存属性的工具,如分配、释放、碎片率等
kvm 用于跟踪/测量KVM虚拟机操作系统性能的工具
list 列出所有符号事件类型
lock 分析系统中锁的获取和释放行为,包括锁竞争、等待时间等,有助于发现潜在的并发瓶颈
mem 对内存访问模式进行分析,包括页错误、缓存未命中的次数、内存带宽使用等。
record 执行命令并将其性能概要记录到perf.data中
report 读取perf.data(由perf record创建)并显示概要
sched 用于跟踪/测量调度器属性(延迟)的工具,从而优化进程调度策略。
script 读取perf.data(由perf record创建)并显示跟踪输出
stat 执行命令并收集性能计数器统计信息
test 运行内置的一系列sanity测试,确保perf工具自身正确性和稳定性。
timechart 工具用于可视化工作负载期间的系统整体行为
top 系统性能分析工具,类似于Linux的top命令,但专注于性能分析,显示正在运行进程的实时性能统计数据。
version 显示perf二进制文件的版本信息
probe 定义新的动态跟踪点,使得perf能够追踪和记录自定义的内核函数或模块行为。
trace 类似strace的工具,用于跟踪系统调用和信号
4. 安装指南
以Ubuntu 20.04为例:
终端输入:
$ sudo apt-get update
$ sudo apt-get install linux-tools-common linux-tools-$(uname -r)
验证:
$ perf --version
输出版本信息则安装成功:
perf version 6.8.12
5. Perf的使用
5.1 查看perf支持的监控event:
$ sudo perf list
List of pre-defined events (to be used in -e or -M):
alignment-faults [Software event]
bpf-output [Software event]
cgroup-switches [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
duration_time [Tool event]
user_time [Tool event]
system_time [Tool event]
cpu_atom:
L1-dcache-loads OR cpu_atom/L1-dcache-loads/
L1-dcache-load-misses OR cpu_atom/L1-dcache-load-misses/
L1-dcache-stores OR cpu_atom/L1-dcache-stores/
L1-icache-load-misses OR cpu_atom/L1-icache-load-misses/
dTLB-loads OR cpu_atom/dTLB-loads/
5.2 使用perf stat查看程序运行过程中各种event的统计:
命令格式:
perf stat [options] [<command>]
以test程序为例,test是test.c文件编译后的可执行文件
$ sudo perf stat -a -e cpu-clock ./test # 使用 CPU 时钟事件
Performance counter stats for 'system wide':
31,484.33 msec cpu-clock # 8.000 CPUs utilized
3.935464050 seconds time elapsed
如上所示,统计了CPU 时钟事件在程序运行过程中的计数,可以使用-e选项来自定义使用的event
5.3 使用perf record和perf report命令来进行更详细的分析:
Important
perf stat命令只能记录event发生的次数,perf record在此基础之上可以记录event发生时详细的数据(比如IP、堆栈等等)。可以自定义需要记录的event,可以自定义记录数据的格式
命令格式:
perf record [options] [command]
perf report [-i perf.data] [options]
实测如下(以test程序为例):
$ sudo perf record -g -F 99 ./test
$ sudo perf report -g -i perf.data # 查看报告
Samples: 1 of event 'task-clock:ppp', Event count (approx.): 10101010
Children Self Command Shared Object Symbol
+ 100.00% 100.00% test [kernel.kallsyms] [k] queue_work_on
+ 100.00% 0.00% test libc.so.6 [.] __GI___libc_write
+ 100.00% 0.00% test [kernel.kallsyms] [k] entry_SYSCALL_64_after_hwframe
+ 100.00% 0.00% test [kernel.kallsyms] [k] do_syscall_64
+ 100.00% 0.00% test [kernel.kallsyms] [k] x64_sys_call
+ 100.00% 0.00% test [kernel.kallsyms] [k] __x64_sys_write
+ 100.00% 0.00% test [kernel.kallsyms] [k] ksys_write
+ 100.00% 0.00% test [kernel.kallsyms] [k] vfs_write
+ 100.00% 0.00% test [kernel.kallsyms] [k] tty_write
+ 100.00% 0.00% test [kernel.kallsyms] [k] file_tty_write.constprop.0
+ 100.00% 0.00% test [kernel.kallsyms] [k] iterate_tty_write
+ 100.00% 0.00% test [kernel.kallsyms] [k] n_tty_write
+ 100.00% 0.00% test [kernel.kallsyms] [k] process_output_block
+ 100.00% 0.00% test [kernel.kallsyms] [k] pty_write
+ 100.00% 0.00% test [kernel.kallsyms] [k] tty_insert_flip_string_and_push_buffer
-
perf record默认只使用了1种event cpu-clock,cpu-clock使用的是高精度定时器来进行定时采样
-
-F 99选项指定了采样频率99HZ
-
-g选项指定了输出数据中包含调用堆栈
-
perf record默认数据输出文件为perf.data
6. 火焰图
Note
火焰图是用图形化的方式来展现perf等工具采集的性能数据,对数据进行统计和分析,方便找出性能热点
火焰图的特点如下:
-
可视化堆栈跟踪: 火焰图将多个堆栈跟踪(stack traces)合并在一起,形成一个层次分明的图表。每个函数调用形成一个矩形,宽度表示函数在CPU上执行的时间占比,高度表示函数调用的层级
-
直观揭示性能瓶颈: 通过观察火焰图,可以直观地看到哪些函数在执行过程中占据了大量的CPU时间,从而快速定位潜在的性能瓶颈
-
排序方式: x轴通常按照函数名称字母顺序排列,而不是时间顺序。这样做的好处是可以很容易地对比相似函数在整个程序中的开销
-
颜色编码: 图中的每个矩形(或称“火焰条”)通常使用随机颜色,目的是在视觉上更容易区分相邻的函数调用。有些变种火焰图可能会采用不同的颜色方案来区分不同的代码区域或模块
-
分析数据来源: 火焰图的数据来源于性能分析工具(如Linux中的perf工具)收集的CPU采样数据,或者是通过其他性能分析手段得到的调用栈信息
-
应用领域: 火焰图广泛应用于性能优化、故障排查、代码重构等领域,尤其适合大型复杂软件系统,有助于工程师们快速理解和改进程序性能
6.1 下载火焰图工具
$ git clone https://github.com/brendangregg/FlameGraph.git
6.2 生成火焰图
下面是一个实际例子(以test程序为例),我们首先用perf record抓取perf数据,再使用脚本生成火焰图:
$ sudo perf record -g -F 99 -- ./test
$ sudo perf script -i perf.data > out.perf
$ /home/lihe/github/FlameGraph/stackcollapse-perf.pl out.perf > out.floded
$ /home/lihe/github/FlameGraph/flamegraph.pl out.floded > test.svg
Note
/home/lihe/github/FlameGraph/ 为火焰图工具绝对路径
6.3 查看火焰图
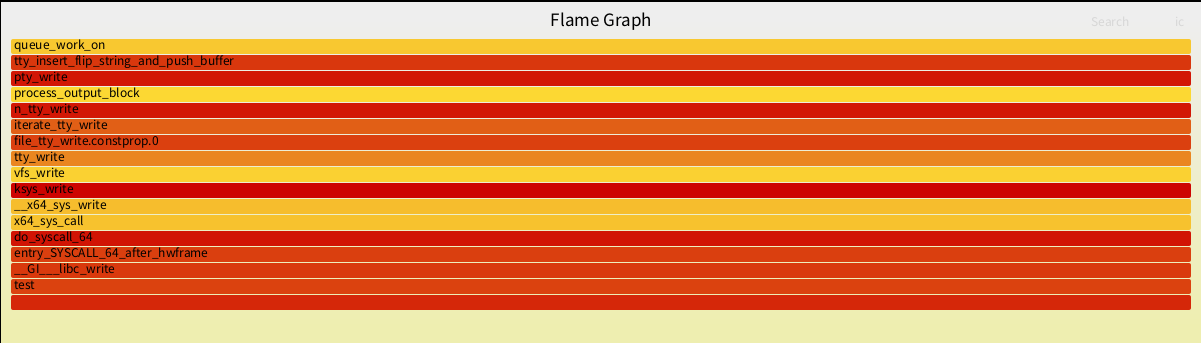
可以看到目录下生成了test.svg文件:
打开test.svg:
Important
火焰图中的每一个方框是一个函数,方框的长度,代表了它的执行时间,所以越宽的函数,执行越久。火焰图的楼层每高一层,就是更深一级的函数被调用,最顶层的函数,是叶子函数
6.4 火焰图的含义
-
火焰图是基于 stack 信息生成的 SVG 图片, 用来展示 CPU 的调用栈
-
y 轴表示调用栈, 每一层都是一个函数. 调用栈越深, 火焰就越高, 顶部就是正在执行的函数, 下方都是它的父函数.
-
x 轴表示该函数执行消耗的时间,横向上会按照字母顺序排序,而且如果是同样的调用会做合并(注意:如果一个函数在 X 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长,所以这里不是严格意义上的执行消耗的时间),所以一个横向宽度越大的函数调用,一般很可能是程序的瓶颈。
-
火焰图的颜色是随机分配的,并不是颜色越深就是越瓶颈。因为火焰图表示的是 CPU 的繁忙程度,所以一般都是暖色调。我们需要留意的就是那些比较宽大的火苗。只要有"平顶",就表示该函数可能存在性能问题。
Tip
对于正在运行的程序 可以直接使用 pert stat -p pid 或者perf record -g -e cpu-clock -pid生成perf.data数据用于分析
6.5 生成红蓝差分火焰图
在某些情况下我们关心的是加上某项功能后,性能的对比情况。这种情况下需要用到差分火焰图来进行分析:
对test程序进行优化后的test1程序进行生成火焰图,并生成红蓝差分火焰图:
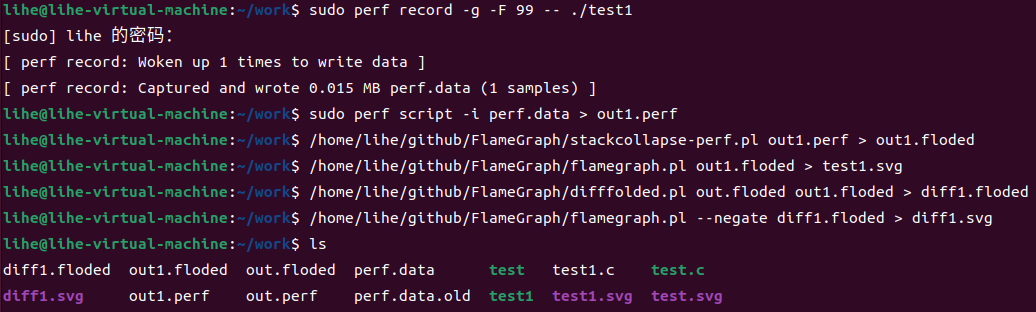
test1程序火焰图test1.svg:

红蓝差分火焰图diff1.svg:

Note
在红/蓝差分火焰图中, 使用不同的颜色来表示两个文件中的差异部分。红色表示增长, 蓝色表示衰减(图中没有红色)
Warning
虽然红/蓝差分火焰图很有用, 但实际上还是有一个问题 : 如果一个代码执行路径完全消失了, 那么在火焰图中就找不到地方来标注蓝色. 你只能看到当前的 CPU 使用情况, 而不知道为什么会变成这样.一个办法是, 将对比顺序颠倒, 画一个相反的差分火焰图
6.6 oncpu/offcpu
以上都是on-cpu火焰图,理解了系统的CPU的走向的分析。但是,很多时候,单纯地看on-cpu的情况(什么代码在耗费CPU),并不能解决性能问题,因为有时候性能差的原因瓶颈不一定在CPU上面,而是在off-cpu的时间,比如:
-
进程进入系统调用执行io动作,io动作的延迟
-
进程等待mutex锁的时间
-
内存被交换,swap的时间
-
内存不够的时候,执行直接内存回收的时间
-
进程被抢占调度走、或者时间片用完被调度走的时间(runqueue太大)
Tip
这一类数据使用bpfcc-tools来采样,具体使用可以参考:用off-cpu火焰图进行Linux性能分析(查阅资料)